
Windowsで文字化けが起きると、ファイルが壊れたように見えて一気に焦ってしまいます。
しかし実際には、原因の多くは文字コードの不一致やアプリごとの読み取り方の違い、フォント不足など、順番に確認すれば切り分けできるものです。
逆に、原因を見極めないまま上書き保存してしまうと、もともとは表示だけの問題だったのに、本当にデータを崩してしまうこともあります。
この記事では、Windowsで文字化けが起きたときに、最初にやるべき安全な確認手順から、ファイル形式ごとの直し方、再発を防ぐ運用ルールまでを初心者向けにわかりやすく整理しました。
「今すぐ読めるようにしたい」という人はもちろん、「次から同じ失敗をしたくない」という人にも役立つ内容です。
よくあるCSVやExcelのトラブル、コマンドプロンプトやPowerShellでの表示崩れ、HTMLやメールでの文字化けまで順番に触れていくので、自分の状況に近いところから読み進められます。
| よくある悩み | この記事での解決ポイント |
|---|---|
| 急に日本語が読めなくなった | 原因を切り分ける順番がわかる |
| CSVやExcelだけ文字化けする | 開き方と保存形式のコツがわかる |
| Windowsの設定も関係していそう | システムロケールやコードページの見方がわかる |
| 二度と再発したくない | 運用ルールの作り方がわかる |
文字化けは、正体がわかれば必要以上に怖いトラブルではありません。
まず何を確認し、どこから直せばいいのかを、このあと順番に見ていきましょう。
この記事でわかること
- Windowsで文字化けが起きる主な原因
- 文字コード・フォント・破損の見分け方
- TXT・CSV・Excel・HTMLなど形式別の直し方
- 再発を防ぐ保存ルールと受け渡しのコツ
文字化けしたときに最初にやること
Windowsで文字化けを見つけたら、最初にやるべきことはすぐに上書き保存しないことです。
文字化けは見た目の問題だけでなく、間違った文字コードで保存し直したことで元の情報まで失われることがあるからです。
とくに.txtや.csvのようなテキスト系ファイルは、開いたアプリの設定次第で内容が崩れたまま保存されることがあります。
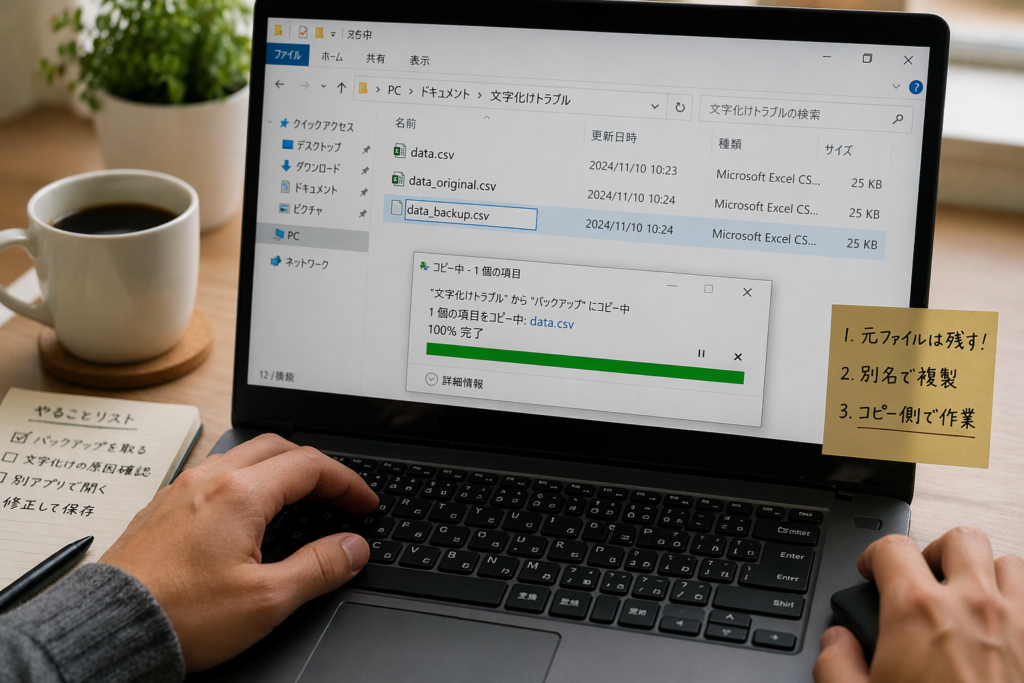
最初の1手は「複製を作る」「元ファイルを残す」「別アプリで再確認する」の3つで十分です。
上書きする前にバックアップを取る理由
結論として、文字化け対応では復旧より先に保全を優先するべきです。
なぜなら、文字化けの原因が「表示だけの問題」なのか「保存内容そのものが崩れている」のかは、開いた瞬間には判断しにくいからです。
たとえばUTF-8のファイルをShift_JIS前提のアプリで開き、そのまま保存すると、見た目の崩れが本当のデータ破損に変わることがあります。
そのため、作業前に次の順で複製を作るのが安全です。
- 元ファイルを別フォルダへコピーする
- ファイル名に「_original」「_backup」を付ける
- 復旧作業はコピー側だけで行う
バックアップを先に取っておけば、途中で別の文字コードを試しても元に戻しやすくなります。
初心者ほど、ここを省略しないことが結果的な最短ルートです。
文字化けが起きている場所を切り分ける方法
文字化けを早く直したいなら、まずどこで崩れているかを切り分ける必要があります。
理由は、同じ「文字化け」に見えても、原因がファイル本体・表示アプリ・Windows設定・フォント不足でまったく変わるからです。
確認は難しくありません。
次の順番で見ると、かなりの確率で原因の方向性が見えてきます。
- そのファイルを別のアプリで開く
- 別のPCや別ユーザー環境で開く
- 同じアプリで別ファイルは正常か確認する
- 拡張子と実際の中身が一致しているか見る
たとえば.csvがExcelでは崩れるのに、テキストエディタでは正常に見えるなら、ファイル破損ではなく読み込み時の文字コード解釈が怪しいと判断しやすくなります。
一方で、どのアプリでも同じように崩れるなら、保存時点の問題や破損も視野に入ります。
ファイル・アプリ・表示環境のどこに原因があるか整理するコツ
切り分けを早くするコツは、原因候補を3つに分けて考えることです。
つまり「ファイル側」「アプリ側」「環境側」です。
| 原因の場所 | 代表例 | 見分け方 |
|---|---|---|
| ファイル側 | 保存時の文字コード違い、破損、バイナリ混入 | どのアプリでも崩れやすい |
| アプリ側 | 読み込み時の自動判定ミス、既定設定の違い | 別アプリでは正常に開ける |
| 環境側 | フォント不足、システムロケール、コードページ | 別PCでは正常に見えることがある |
この整理を先にしておくと、関係ない設定まで触ってしまう無駄を減らせます。
Windowsの文字化けが起きる仕組み
Windowsの文字化けは、ほとんどの場合、保存した文字コードと表示側が想定した文字コードが一致していないことで起きます。
つまり、データそのものが別の言語で壊れているのではなく、読み方を間違えているケースが多いです。
この仕組みがわかると、対処法も一気にわかりやすくなります。
文字化けはなぜ起きるのか
文字化けは、文字と数字の対応表がずれたときに起こります。
コンピューターの中では、文字はそのまま保存されているのではなく、一定のルールに沿って数値へ変換されています。
このルールが文字コードです。
たとえば、保存時にはUTF-8で書かれたデータを、表示側がShift_JISだと思って読めば、本来の日本語として復元できず、記号や意味不明の文字列になります。
文字化けは「保存ミス」だけでなく「読み取りミス」でも発生すると覚えておくと整理しやすいです。
UTF-8・Shift_JIS・CP932・BOMの違い
初心者が最初に押さえるべきなのは、よく出てくる4つの用語です。
| 用語 | 意味 | 覚え方 |
|---|---|---|
| UTF-8 | 現在もっとも広く使われるUnicode系の文字コード | Webや新しいツールで主流 |
| Shift_JIS | 日本語Windowsで長く使われてきた文字コード | 古い業務データやCSVで残りやすい |
| CP932 | Windows系日本語環境で実質的に使われるShift_JIS系拡張 | Windows特有の互換差が出やすい |
| BOM | ファイル先頭に付く識別用の印 | UTF-8かどうかの判定補助になることがある |
特に厄介なのは、UTF-8でもBOMありとBOMなしで挙動が変わるアプリがある点です。
そのため、単に「UTF-8だから安全」とは言い切れません。
保存時と表示時の不一致で起きる代表パターン
文字化けの典型は、保存時と表示時の想定がずれるパターンです。
代表例を見ておくと、実際の調査が速くなります。
| 保存時 | 表示時 | 起こりやすい結果 |
|---|---|---|
| UTF-8 | Shift_JISとして開く | 「ã」「æ」などが並ぶ |
| Shift_JIS | UTF-8として開く | 日本語が記号や空白になる |
| UTF-8 BOMなし | BOM前提のアプリで開く | 自動判定に失敗することがある |
| 正常な文字列 | 対応フォント不足 | □や豆腐表示になる |
このように、見た目だけで決め打ちせず、保存形式と開き方の両方を見ることが大切です。
原因を見分けるチェックポイント
文字化けを直す近道は、原因を3系統に分けて見分けることです。
つまり、エンコーディング不一致、フォント不足、破損や混入です。
ここを誤ると、フォントの問題なのに文字コードばかり変えたり、逆に破損ファイルを何度も別形式保存して悪化させたりします。
エンコーディング不一致を疑う症状
もっとも多いのは、エンコーディング不一致です。
この場合は、崩れ方に一定の規則性があります。
- 「ã‚」「æ–‡」のように読めそうで読めない文字列が出る
- 一部だけ正常で、日本語だけ崩れる
- 別の文字コードで開くと突然読める
- 同じファイルでもアプリごとに見え方が違う
この症状なら、まず文字コード切り替えを優先して試す価値があります。
逆に、完全に空白や四角ばかりなら、別原因の可能性もあります。
フォント不足とグリフ欠落を疑う症状
□や?や別記号に見える場合は、フォント側の問題も疑うべきです。
これはデータが壊れているのではなく、その文字を表示できる字形が見つからない状態です。
たとえば、特殊な中国語・韓国語・機種依存文字・古い外字などは、環境によっては表示できません。
見分け方はシンプルです。
別フォントへ変更したら直る、別PCでは見える、PDFだけ崩れる、といった場合はフォント関連の可能性が高くなります。
文字コードの変更で改善しないときは、フォントの存在確認へ進むのが効率的です。
改行コード・BOM・ファイル破損を疑う症状
文字化けの中には、エンコーディングそのものではなく、BOMや改行コード、ファイル破損が絡むケースもあります。
たとえば先頭に見慣れない文字が出る、1行目だけ崩れる、途中で急に表示が乱れるなら、この系統を疑います。
また、テキストファイルのはずなのに途中にバイナリデータが混ざっていると、アプリによっては先頭だけ正常で後半だけ崩れることもあります。
サイズが不自然に大きい、拡張子に対して中身が一致しない、別エディタで制御文字が多い場合は、破損や混入の確認が必要です。
すぐ試せる直し方
ここからは、初心者でも実行しやすい対処法を順番に紹介します。
結論としては、まずアプリ側の読み取り方法を変え、それでもダメならWindows側の設定を見る流れが安全です。
メモ帳・Notepad++・VS Codeで文字コードを切り替える手順
もっとも手軽なのは、テキストエディタで別の文字コードとして開き直す方法です。
理由は、元ファイルを壊さずに表示確認しやすいからです。
手順の考え方はどのエディタでも共通しています。
- ファイルを開く
- 現在の文字コード表示を確認する
- UTF-8、Shift_JIS、UTF-8 BOMあり付近を順に試す
- 正しく見えたら別名保存で保存形式を整える
Notepad++ではエンコードメニューから再解釈しやすく、VS Codeではステータスバーのエンコード表示から再オープンや保存時変更がしやすいです。
ここで重要なのは、正しく見える前に上書き保存しないことです。
正しく見えた後も、元の運用先が何を想定しているか確認してから保存形式を決めてください。
コマンドプロンプトの chcp を使う場面
コマンドプロンプトで日本語が崩れる場合は、chcp が役立ちます。
これはコンソールのアクティブコードページを切り替えるためのコマンドです。
たとえば現在の状態確認には次を使います。
chcpUTF-8系で試すなら次のように切り替えます。
chcp 65001ただし、これは主にコンソール表示や入出力の見え方に関わる対処であり、ファイル本体の中身を書き換えるものではありません。
そのため、テキストファイル復旧の万能策ではなく、コマンドライン上での文字化け確認や一時的な作業環境調整に使うのが適切です。
ブラウザ・メールで一時的に表示を直す方法
ブラウザやメールで文字化けするときは、送受信データそのものより、表示側の解釈がずれていることがあります。
WebページならHTML側の文字セット宣言不足や、サーバー側の送信設定ズレが原因になりやすいです。
メールなら送信時の文字コード自動選択や、受信側クライアントとの相性で崩れることがあります。
一時対処としては次を確認します。
- ブラウザでソース上の文字コード宣言を確認する
- HTML先頭付近に文字セット指定があるか見る
- メールソフトのエンコード自動選択を見直す
- 別のメールクライアントやWebメールでも表示確認する
ただし一時的に見え方が直っても、送信元やHTML本体の設定が不整合なら再発します。
ファイル形式ごとの対処法
文字化けはファイル形式によって最適な直し方が変わります。
ここでは、よくあるTXT、CSV、Excel、HTML、メール、PDFをまとめて整理します。
TXTファイルの直し方
TXTはもっとも単純に見えて、実は文字コードの影響を強く受ける形式です。
なぜなら、テキスト本体しか持たないため、どの文字コードかを外部の判断に頼る場面が多いからです。
復旧の基本手順は次の通りです。
- バックアップを取る
- 別エディタでUTF-8とShift_JISを順に試す
- 正しく見えた状態を確認する
- 運用先に合わせて別名保存する
保存先がWebや複数OSならUTF-8が扱いやすいです。
一方で古いWindows業務アプリへ渡すならShift_JIS系が必要なこともあります。
重要なのは「自分が読みやすい形式」ではなく、「次に使う相手が正しく読める形式」で保存することです。
CSVとExcelの文字化けを防ぐ読み込み方
CSVは文字化け相談が非常に多い形式です。
理由は、CSV自体が列区切りの約束しか持たず、文字コード情報を強く持たないためです。
Excelで安全に扱うなら、ダブルクリックで開く前提をやめるのが効果的です。
まずExcelを起動し、データ取り込みからCSVを読み込む流れにすると、文字コードを確認しながら開きやすくなります。
また、UTF-8 CSVはBOM付きであれば通常オープンしやすい一方、BOMなしではインポート経由のほうが安定しやすい場面があります。
| 状況 | おすすめ対応 |
|---|---|
| 日本語CSVをExcelで直接開くと崩れる | Excelのインポート機能から読み込む |
| 他システムへ渡すCSVを作る | 相手の対応文字コードを事前確認する |
| 保存形式を迷う | CSV UTF-8と従来CSVを用途別に使い分ける |
Excel運用では、「開き方」と「保存形式」をセットでルール化することが再発防止に直結します。
HTML・メール・PDFで確認したいポイント
HTMLでは、ファイル自体の文字コードと宣言が一致しているかが重要です。
ページ内の記述がUTF-8でも、文字セット宣言がずれていればブラウザの解釈が狂うことがあります。
メールでは、送信側のエンコード設定と受信側クライアントの相性を見ます。
PDFでは、文字コードよりもフォント埋め込みや表示フォントの差で崩れて見えるケースもあります。
つまり、HTML・メール・PDFは同じ「文字化け」でも中身が異なります。
- HTMLは文字セット宣言と保存形式の一致
- メールは送信設定と受信側表示の確認
- PDFはフォントと生成方法も確認
この切り分けをしてから対処すると、遠回りを避けやすくなります。

Windows固有の設定で直るケース
アプリだけでは直らないときは、Windows側の設定が関係していることがあります。
ただし、ここは影響範囲が広いため、やみくもに変更せず、条件が一致したときだけ触るのが安全です。
非Unicodeプログラム向けのシステムロケール変更が有効な場面
古いWindowsアプリや非Unicode前提の業務ソフトでは、システムロケールが表示に影響することがあります。
これは「非Unicodeプログラム用の言語」設定に近い考え方で、レガシーアプリの既定コードページに関係します。
もし特定の古いソフトだけで日本語が崩れ、ほかの新しいアプリは問題ないなら、この設定が関係している可能性があります。
ただし、変更後は再起動が必要になり、別の古いアプリへ影響することもあります。
そのため、変更前には現在の状態を記録し、業務ソフトの対象範囲を確認してから実施するのが無難です。
PowerShellとコマンドプロンプトでのエンコードの注意点
Windowsでは、PowerShellとコマンドプロンプトで文字の扱いが同じとは限りません。
そのため、同じファイルでも、開く場所や出力方法によって見え方が変わることがあります。
特に自動処理では、画面表示だけ正常でも保存ファイルが期待どおりとは限りません。
スクリプト化する場合は、出力時のエンコードを明示しておくと事故を減らせます。
たとえば、ログ出力やCSV生成では既定任せにせず、保存形式を指定する運用が安全です。
# 例:UTF-8で保存する意図を明示する
$data | Set-Content -Path ".\sample.txt" -Encoding utf8重要なのは、コンソール表示の調整とファイル保存時のエンコード指定は別物だと理解することです。
UTF-8のBOMあり・なしをどう使い分けるか
BOMあり・なしで迷ったら、相手の受け取り先を基準に決めるべきです。
Webや最近の開発ツールではBOMなしが扱いやすいことが多い一方、Windows系の一部アプリやExcel連携ではBOMありが判定補助になることがあります。
つまり、正解は1つではありません。
| 使い分けの目安 | 向いていることが多い形式 |
|---|---|
| Webページ、スクリプト、他OSとの連携 | UTF-8 BOMなし |
| Windows向けCSV受け渡し、判定重視 | UTF-8 BOMあり |
| 古い日本語Windows業務環境 | Shift_JIS系を要確認 |
「全部UTF-8に統一」で終わらせるのではなく、運用先まで含めて統一することが大事です。
再発防止のための運用ルール
文字化けは、その場で直すだけだと再発しやすいトラブルです。
本当にラクになるのは、次回以降に起こしにくい運用へ変えることです。
保存形式を先に決めるルール
再発防止の基本は、保存形式を人ごとに変えないことです。
担当者ごとにUTF-8、Shift_JIS、Excel直接保存が混ざると、同じ業務でも毎回事故の温床になります。
そこで、最低でも次の3点は決めておくと安定します。
- 標準の文字コード
- BOMあり・なしの扱い
- CSVを直接開くか、インポートするか
短い手順書でもよいので、保存前提を先に統一しておくと、個人依存を減らせます。
CSV受け渡しで失敗しにくい手順
CSV運用では、送る側と受ける側の認識合わせが最重要です。
おすすめは、ファイルだけ渡さず、次の情報も一緒に共有することです。
- 文字コードはUTF-8かShift_JISか
- BOMありかなしか
- 区切り文字はカンマかタブか
- Excelは直接開かずインポートするか
これだけで「こちらでは見えるのに相手では崩れる」というトラブルがかなり減ります。
テンプレートや送付文の定型を作っておくと、運用が安定します。
トラブル時に残すべき情報とチェックリスト
再発防止では、問題発生時の記録も重要です。
毎回ゼロから調べるより、証拠を残したほうが早く正確に直せます。
最低限、次の情報は残しておくと便利です。
- 元ファイル名と複製ファイル名
- 拡張子
- 開いたアプリ名とバージョン
- 開き方
- 正常だった環境と異常だった環境
- 試した文字コード
- 症状のスクリーンショット
これらがあるだけで、次回は「同じ原因か」「別の原因か」を短時間で判断しやすくなります。
文字化けは面倒ですが、切り分けの型を持っておけば必要以上に怖がる必要はありません。
まとめ
この記事のポイントをまとめます。
- 文字化けを見つけたら、最初に元ファイルをバックアップすることが大切です。
- 文字化けは、保存時と表示時の文字コードの不一致で起きることが多いです。
- UTF-8・Shift_JIS・CP932・BOMの違いを知るだけで原因の切り分けがしやすくなります。
- 別アプリや別PCで開いてみると、ファイル側か環境側かを見分けやすくなります。
- □表示や一部文字だけの崩れは、フォント不足やグリフ欠落の可能性があります。
- TXTはエディタで文字コードを切り替えながら、正しく見える状態を探すのが基本です。
- CSVはExcelで直接開くより、インポート機能を使ったほうが失敗しにくいです。
- コマンドプロンプトの
chcpは表示環境の調整に有効ですが、ファイル自体を直すものではありません。 - 古い非Unicodeアプリでは、Windowsのシステムロケールが影響することがあります。
- 再発防止には、保存形式・受け渡し方法・記録ルールの統一が最重要です。
Windowsの文字化けは、最初は難しそうに見えても、原因のパターンはある程度決まっています。
大切なのは、焦って設定を片っ端から触るのではなく、バックアップ→切り分け→適切な修正→運用の見直しという順番を守ることです。
この流れで対応すれば、その場しのぎではなく、次回以降も迷わず対処しやすくなります。
「どこで崩れたのか」を先に見極めることが、最短復旧へのいちばん確実な近道です。

